一、前言:為什麼 AI Agent 需要「長期記憶」?
- 當前多數 AI 對話模型僅具備「短期上下文」處理能力
- 真正具備自主性與個人化服務的 Agent,需要能記住用戶資訊、偏好與歷史互動
- 長期記憶讓 AI 從「對話引擎」升級為「智慧助理」
二、AI 記憶的分類與挑戰
🔹 記憶分類
- 短期記憶(Working Memory): 限定在當前對話上下文(如 ChatGPT token 限制)
- 中期記憶(Session Memory): 在一段使用期間內維持狀態(如連續對話保持人名、任務)
- 長期記憶(Long-term Memory): 存儲跨任務、多日、多主題的資料與概念
🔸 實作挑戰
- 記憶容量與摘要策略
- 記憶的持久化與檢索效率(Embedding + Vector DB)
- 隱私與權限控管(用戶是否同意儲存?能否刪除?)
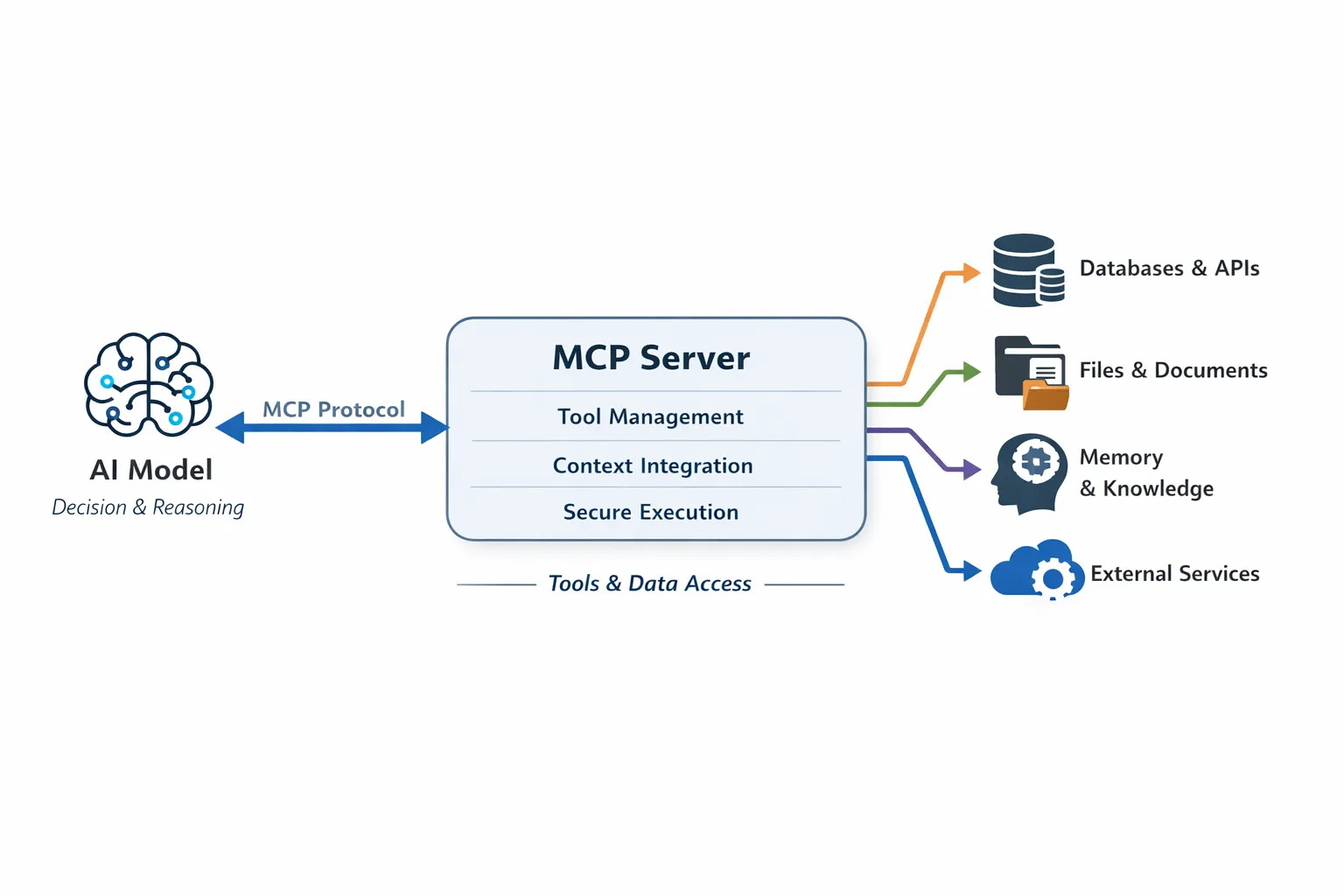
三、設計長期記憶功能的核心流程
① 使用者輸入 → 向量化(Embedding)
📌 說明:
使用者在與 AI Agent 對話時,每一句話(或每段上下文)都會先被轉換成「向量格式」,這是讓 AI 能進行語意理解與比對的第一步。
🛠 技術細節:
- 常用 API:OpenAI Embedding API(
text-embedding-3-small、text-embedding-ada-002) - 對話轉換方式:將文字內容轉為高維數字向量(例如 1536 維的浮點數陣列)
- 可以只選摘要過的資訊(如:「使用者設定儲蓄目標:每月存 500 美元」)
✅ 實用技巧:
- 可設定「摘要器」,自動濃縮可記憶重點,再進行向量化
- 重要對話(如:使用者設定、目標)可標記為「強記憶」
② 檢索記憶(Vector Search)
📌 說明:
將當前對話向量與歷史對話中已存的記憶向量進行比對,檢索出「語意最相關」的記憶,作為本次回應的補充資訊。
🛠 技術細節:
- 常用工具:Pinecone、Weaviate、Chroma、FAISS
- 向量比對方式:使用餘弦相似度(Cosine Similarity)計算相似度
- 通常只取 Top-k(例如 3~5 則)相關記憶
✅ 實用技巧:
- 可設定語意相似度閾值(如 >0.78 才列入)
- 結合時間戳 + 熱度機制(近期對話或常被提及者權重較高)
③ 合併上下文 → 傳送給 GPT 回應生成
📌 說明:
將使用者輸入與檢索到的記憶內容「一併提供給模型」,讓 GPT 能根據更完整的上下文做出個人化回應。
🛠 技術細節:
- 記憶插入方式:
system prompt:例如「你過去記得用戶喜歡存錢但不擅長記帳」context block:以提示詞加入類似「以下是你對這位使用者的長期記憶摘要…」
- 搭配工具:LangChain、LlamaIndex 都有支援記憶插入模組
✅ 實用技巧:
- 若記憶太多,可用摘要壓縮(例如 GPT 幫你寫「使用者偏好總結」)
- 可根據任務類型(客服、教學、理財)調整記憶權重與篩選邏輯
④ 回應後 → 儲存新記憶
📌 說明:
AI Agent 回應完後,需將這次有價值的資訊存入長期記憶,形成一個「動態學習循環」。
🛠 技術細節:
- 可將「回應摘要」與「使用者關鍵回覆」自動提取、向量化後存入資料庫
- 結合 JSON Schema 結構化記憶(如 name, goal, preference, last_topic)
✅ 實用技巧:
- 記憶應包括來源、時間戳記、摘要、回應編號
- 若記憶過多,可加上 LLM 回饋壓縮機制(例如每週重新摘要最常提及主題)
📦 建議搭配工具資源:
| 類別 | 工具 / API |
|---|---|
| 向量化 | OpenAI Embedding |
| 向量資料庫 | Pinecone、Weaviate、Chroma |
| 開發框架 | LangChain、LlamaIndex |
| JSON 結構記憶儲存 | Firebase Realtime DB、Supabase、MongoDB |
四、主流程設計範例(技術架構)
複製編輯使用者輸入 → 向量化(OpenAI Embedding API) → 檢索記憶(Pinecone)→ 合併上下文 → GPT 回應 → 如有新記憶 → 儲存向量 + 摘要
- 可搭配 LangChain / LlamaIndex 進行記憶模組化設計
- 使用工具建議:
五、應用實例
✅ 客製化學習助理
- 記得使用者的學習進度、錯誤常見點、學習目標
✅ 自動化客服系統
- 長期記錄客戶過往詢問紀錄、偏好回覆方式、產品購買歷史
✅ AI 理財顧問
- 記住使用者財務目標、花費習慣、風險偏好,主動提供預測與建議
六、進階記憶管理:記憶壓縮與多層記憶模型
- 壓縮策略: 以摘要 + 關鍵片段保存,不需每則對話原文儲存
- 分層記憶設計:
- Fast Memory(近期用過、常用)
- Stable Memory(核心事實、Profile)
- Archive(冷資料,查詢需求低)
七、隱私與使用者授權設計
- 明確提示哪些資料將被記憶、可選擇是否存儲
- 提供「記憶查詢與管理」界面(如 ChatGPT Memory)
- GDPR 合規設計:允許一鍵刪除所有記憶紀錄
八、總結:AI Agent 從短期記憶走向「可信任的長期助理」
- 長期記憶讓 AI 從對話機器人進化為「懂你、記得你、幫你規劃未來」的智慧助手
- 開發者在設計 AI Agent 時,需妥善管理記憶的收集、更新與刪除
- 記憶,是未來 AI「人格化」與「情境智慧」的基礎核心